Five Splunk detection capabilities, end to end.
A self-contained Splunk Enterprise POC running on AWS — built in code, deployed by CI, including AI-assisted detection authoring with a human review gate. Every piece of state is reproducible from git in ~15 minutes.
1. Data parsing & ingestion
Approach. Splunk gets data through purpose-built TAs layered over modular inputs. TA-aws account + input stanzas versioned as YAML in taaws-config/config.yml and pushed via REST on every CI run — no UI clicks to reproduce.

tw_cim_accel app overlays props/eventtypes/tags/datamodels.conf so indexed events populate the three accelerated CIM datamodels.What's running
- CloudTrail → S3 → SQS → TA-aws — multi-region management events, ~2,500 events/hour at steady state.
- VPC Flow Logs → S3 → SQS → TA-aws — ~12,000 events/hour, sourcetype
aws:cloudwatchlogs:vpcflow. - CIM Authentication field mapping for CloudTrail in
tw_cim_accel/default/{eventtypes,tags,props}.conf— populatesuser,src,dest,app,signature,actionso the Authentication datamodel actually fills (TA-aws 8.x ships this gap).
Demonstrable artifacts
- terraform/modules/cloudtrail_ingest/ — trail, S3 bucket, SQS, IAM
- terraform/modules/vpc_flow_logs_ingest/ — flow log, S3, SQS, IAM
- taaws-config/config.yml — declarative TA-aws account + inputs
- apps-src/tw_cim_accel/default/ — CIM mapping
.conffiles - Live Splunk Search — run
index=main sourcetype=aws:cloudtrail | head 20 - TA-aws Inputs page — see the two live SQS-Based S3 inputs
2. Data Model Acceleration (DMA)
Approach. CIM-fit first for every detection, raw-SPL fallback second. Acceleration configured as code in tw_cim_accel/default/datamodels.conf; install-apps.sh syncs that file into Splunk_SA_CIM/local/datamodels.conf on every deploy — the only path Splunk reliably honors for DMA overrides (verified the hard way).
What's running
- 3 accelerated CIM datamodels:
Change,Authentication,Network_Traffic. Build cron*/5 * * * *, 7-day backfill, per-DMtags_whitelistfor performance. - DMA Benchmark dashboard (ours, shipped in
tw_cim_accel) — side-by-side|tstatsvs|searchlatency + per-DM acceleration health (summary size, completeness, build-in-progress). - Verified live: 180+ events tagged
authentication(was 0 before our CIM mapping fix), 12,500+ taggednetwork, 100+ taggedchange.
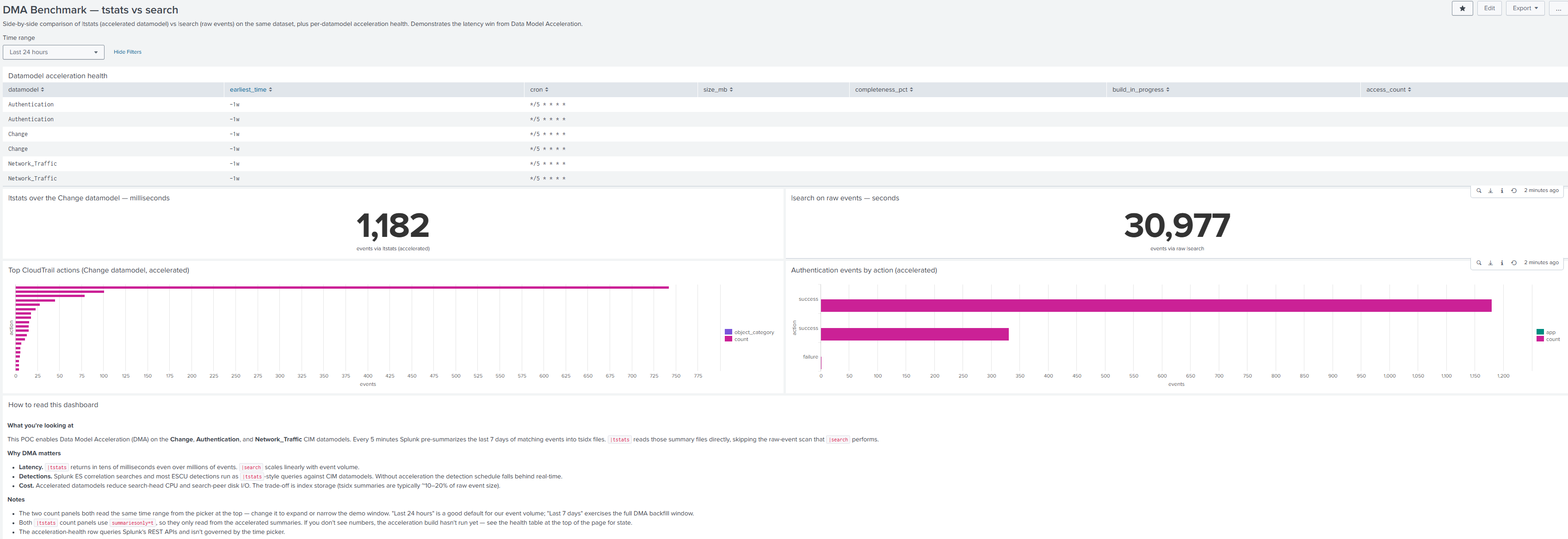
/app/tw_cim_accel/dma_benchmark — |tstats over the accelerated Change datamodel returns in milliseconds vs a raw-event scan over the same dataset.Demonstrable artifacts
- apps-src/tw_cim_accel/default/datamodels.conf — the IaC source-of-truth
- DMA Benchmark dashboard XML
- Live DMA Benchmark dashboard
- Splunk's Datamodels admin page — see acceleration toggled on
3. Splunk detection engineering
Approach. Detection content is YAML, schema-validated, ATT&CK-mapped (against the current v19.1 framework), written in CIM-aligned SPL where the datamodel covers the data and well-documented raw SPL where it doesn't. Every rule is ES-compatible — drops into a licensed ES instance as a correlation search without rewrite.
What's running — 8 detections in detections/aws/
| Detection | ATT&CK | Pattern |
|---|---|---|
| CloudTrail Disabled | T1685.002 | |tstats over datamodel=Change |
| Console Login Without MFA | T1078.004 | raw SPL (MFA flag not in CIM) |
| Console Login Failures Burst | T1110.001 | time-windowed stats |
| IAM CreateAccessKey For Different User | T1098 / T1078.004 | cross-field SPL comparison |
| Security Group Open To World | T1133 / T1190 | spath + mvexpand on nested JSON |
| S3 Bucket Policy Public Write | T1567 / T1530 | raw SPL on policy JSON |
| Root Account Usage | T1078.004 | raw SPL |
| IAM Password Spray Test AI-drafted | T1110.003 | raw SPL, scheduled, alerting |
Each YAML carries: ATT&CK technique IDs, kill-chain phase, CIS/NIST mappings, false-positive tuning hints, prereqs, references to Splunk's security_content, AWS docs, and MITRE.
Demonstrable artifacts
- detections/aws/ — one YAML per rule
- detections/SCHEMA.md — the YAML format spec
- Live saved searches — all 8 scheduled, alerting
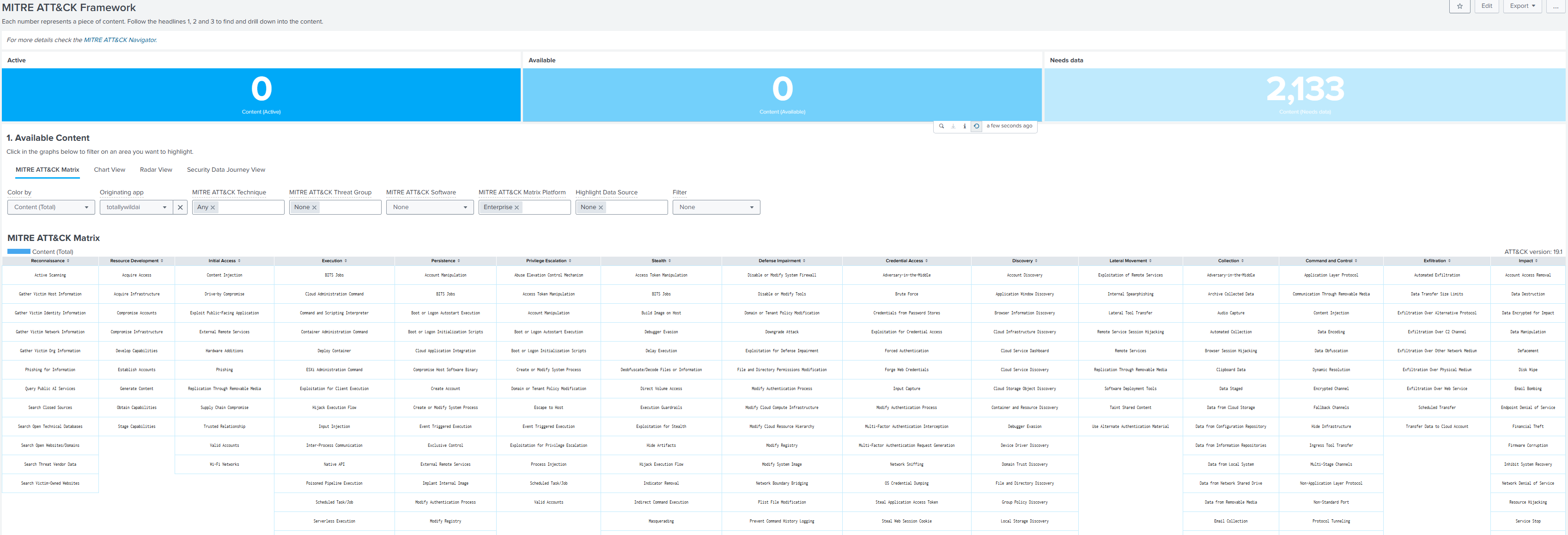
- SSE MITRE ATT&CK heat map — filter Originating app = totallywildai, Color by = Content (Total)
- ESCU app — Splunk's bundled detection catalog for comparison
4. Detections as Code (CI/CD)
Approach. Two-pipeline split — infra changes don't trigger content deploys, content changes don't trigger infra plans. GitHub Actions, OIDC-authenticated AWS access. Zero static credentials; Splunk management port :8089 is never publicly exposed.

install-apps.sh locally — no inbound :8089 needed from the CI runner.Pipelines
terraform.yml
Plan on PR (artifact), apply on push to main. Triggers only on terraform/** changes.
splunk-config.yml — 6 jobs
- validate — YAML schema check on detections;
.confsanity on apps-src (BOM, CRLF, duplicate stanzas) - deploy-apps — builds
.tgzfromapps-src/, syncs to S3, SSM-triggersinstall-apps.sh - deploy-sse-content — REST PUT to SSE
custom_contentKV-store - deploy-detections — REST POST to
/services/saved/searches - deploy-taaws-config — REST POST to
/servicesNS/.../Splunk_TA_aws/data/inputs/aws_sqs_based_s3 - deploy-sse-data-inventory — REST PATCH on
data_inventory_productsKV-store
All four deploys: CI uploads payload to S3, sends one SSM SendCommand, the EC2 fetches + runs locally. No public 8089.
Disaster recovery verified 2026-05-13
terraform apply -replace of the EC2 + workflow re-run brought every piece of state back from git in ~15 minutes total. The rebuild test surfaced one real bug (HTTP 400 vs 404 in TA-aws input REST handler), which is now fixed in code.
Demonstrable artifacts
- .github/workflows/ — both pipelines
- All Actions runs (most recent — all green)
- docs/disaster-recovery.md — full DR runbook
5. AI for detection development
Approach. AI is a junior author with senior-author review. Claude drafts the detection YAML, the existing CI gates the schema, a human reviews the draft PR, merge triggers the same deploy pipeline as a hand-written rule. The authoring loop AND the validation loop run inside the existing repo structure with no bespoke tooling.
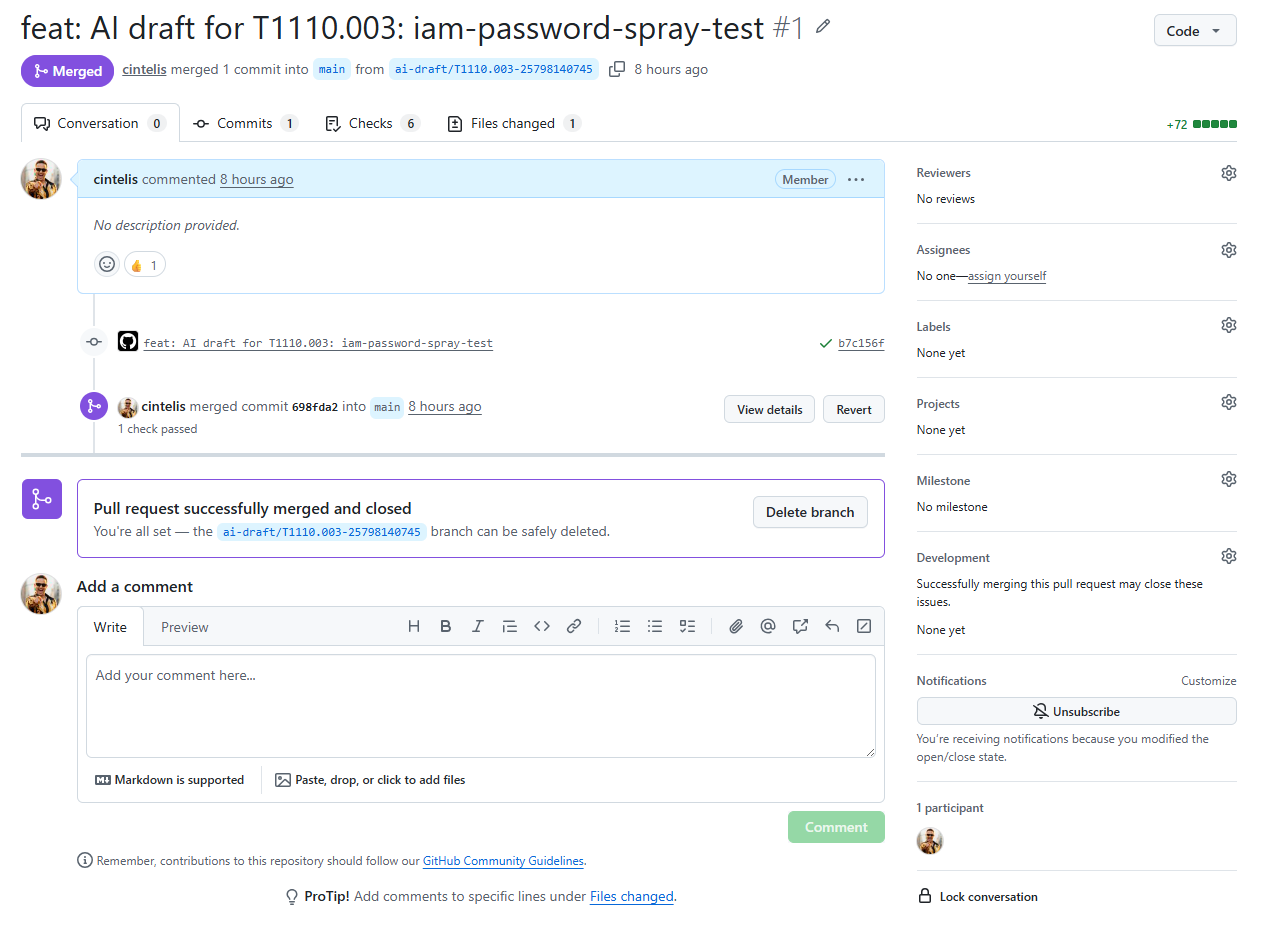
End-to-end demonstrated 2026-05-13
- Operator typed 4 inputs into the GitHub Actions form (
T1110.003/iam-password-spray-test/ "Detects bursts of failed ConsoleLogin events…") - Claude (
claude-sonnet-4-6) drafted a schema-conformant YAML againstSCHEMA.md+ thecloudtrail-disabled.ymlexemplar embedded in the prompt - Draft PR opened automatically with the YAML + reviewer checklist (~30 sec from button click)
- Existing
validateCI job ran — YAML schema-checked clean - Human reviewed the PR + merged
splunk-configworkflow auto-fired on merge → live as a scheduled saved search alerting on production CloudTrail data, every 15 minutes
Guardrails
- Draft PR is a mandatory human gate — workflow opens it as draft, no auto-merge
- Prompt embeds available sourcetypes + CIM datamodels — Claude can't hallucinate fictional data shapes
- UUID and date generated client-side and force-overridden — identity doesn't depend on Claude
- Prompt requires output to mirror exemplar shape — reduces schema drift
Cost: ~$0.005 per draft on Sonnet 4.6 (~3K input + ~800 output tokens).
Demonstrable artifacts
- scripts/ai/draft-detection.py — the drafter CLI + prompt
- .github/workflows/ai-draft-detection.yml — workflow_dispatch trigger
- docs/ai-workflow.md — operator runbook
- The actual end-to-end PR — Claude's draft, merged 2026-05-13
- The AI-drafted YAML as merged to
main - Live in Splunk — filter for "Password Spray"
Capability scorecard
| Capability | Status | Notes |
|---|---|---|
| Data parsing & ingestion | Fully demonstrated | CloudTrail + VPC Flow live; GuardDuty + HEC are obvious next adds for breadth |
| DMA optimization & alignment | Fully demonstrated | 3 CIM datamodels accelerated, benchmark dashboard shipped |
| Detection engineering | Fully demonstrated | 8 rules, ATT&CK v19.1-current, ES-compatible |
| Detections as Code (CI/CD) | Fully demonstrated | 6 CI jobs green, DR-verified, public :8089 never exposed |
| AI for detection development | Fully demonstrated | End-to-end live; an automated Docker-Splunk test runner for AI drafts is Phase 6.1, deferred |